
Scope: ES256 (P-256) COSE_Sign1 size and speed plus post-quantum ML-DSA (FIPS 204), wolfCOSE vs t_cose vs COSE-C, with cross-language and on-device results.
Method: one identical operation, every library and crypto backend built from source on one machine with identical flags, dead-code eliminated. Desktop: x86_64 Intel i9-11950H, GCC 14.2. On-device: NUCLEO-H563ZI Cortex-M33 at 250 MHz. June 2026.
COSE (RFC 9052 / 9053) is how constrained devices sign, verify, encrypt, and MAC small CBOR payloads: firmware manifests, attestation tokens, CWT credentials. On a microcontroller the library you pick shows up directly in flash and in how many signatures per second you can verify. So we measured it, carefully, against the other real COSE implementations.
The short version: wolfCOSE ships the smallest COSE library code, the smallest total footprint with a comparable embedded crypto backend, and the fastest sign and verify throughput. This document shows the exact numbers and, more importantly, exactly how they were produced.
How we measured
Library size is easy to get wrong. Running size over a whole compiled archive counts every function in the library, including code your program never calls. Comparing one library’s full algorithm set against another’s narrow one is not a comparison. Quoting a competitor’s published number built with a different compiler and flags is not a comparison either.
So every number here follows one method:
- One identical operation: ES256 (P-256) COSE_Sign1, the same fixed key and the same payload, in every library.
- Same toolchain, built from source: every library and every crypto backend compiled on one machine (x86_64, GCC 14.2) with identical flags. No distro packages, no published numbers.
- Every competitor fully optimized too: Mbed TLS, t_cose, and QCBOR were each built with their own size and speed options turned on, not a stock or hobbled config. These are the smallest and fastest builds we could produce for every library, so the comparison gives each one its best possible footing.
- Dead-code elimination: compile with -ffunction-sections -fdata-sections, link with -Wl,–gc-sections, so only the functions actually reached by the ES256 Sign1 path remain. This is the real flash cost.
- Per-object attribution: the surviving bytes are attributed from the GNU ld map to buckets (COSE, CBOR, crypto, C++ runtime). We add -fno-merge-constants so string pools are attributed to the right object.
- Cross-checked: the linker map starts with a “Discarded input sections” block. Counting it inflates everything roughly 2x. We caught that by checking the attribution against the stripped binary’s actual size.
- Interop-verified: for the verify numbers, every library verifies the same wolfCOSE-produced message. They all succeed, which proves interoperability at the same time.
Two size numbers are reported. Glue is COSE plus CBOR, the COSE library’s own code, independent of the crypto backend. Total is glue plus the crypto pulled in. All crypto backends were built minimal from source, including OpenSSL.
Size: the COSE library itself
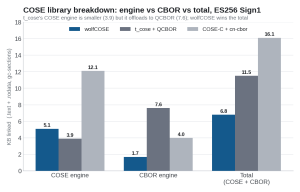
Figure 1. COSE engine vs CBOR engine vs the COSE + CBOR total, ES256 Sign1, all built from source with dead-code elimination.
| Library | COSE engine | CBOR engine | Total(COSE + CBOR) |
|---|---|---|---|
| wolfCOSE (WOLFCOSE_LEAN) | 5.1 KB | 1.7 KB | 6.8 KB |
| t_cose + QCBOR | 3.9 KB | 7.6 KB | 11.5 KB |
| COSE-C + cn-cbor | 12.1 KB | 4.0 KB | 16.1 KB |
This is the fairest, apples-to-apples comparison, and it is where the interesting story is. Look at t_cose: its COSE engine is actually a little smaller than ours (3.9 KB vs 5.1 KB). t_cose achieves that by pushing the work down into QCBOR. The result is that QCBOR is 7.6 KB while our built-in CBOR engine is 1.7 KB.
Verify only COSE sizes
Most on-device deployments only verify (signed firmware, attestation, CWT), so wolfCOSE ships a WOLFCOSE_LEAN_VERIFY profile that compiles in only the COSE_Sign1 verify path. Measured the same way, the verify-only library breakdown tells the identical story, just smaller across the board.
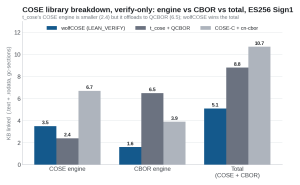
Figure 3. COSE engine vs CBOR engine vs the COSE + CBOR total, ES256 Sign1 verify-only, all built from source with dead-code elimination.
| Library | COSE engine | CBOR engine | Total(COSE + CBOR) |
|---|---|---|---|
| wolfCOSE (WOLFCOSE_LEAN_VERIFY) | 3.5 KB | 1.6 KB | 5.1 KB |
| t_cose + QCBOR | 2.4 KB | 6.5 KB | 8.8 KB |
| COSE-C + cn-cbor | 6.7 KB | 3.9 KB | 10.7 KB |
The pattern from the sign + verify case holds: wolfCOSE keeps the smallest total library at 5.1 KB with a tiny 1.6 KB CBOR engine, while t_cose keeps a thin COSE layer (2.4 KB) but still links 6.5 KB of QCBOR. Stripping the signing path shrinks every library, and wolfCOSE stays the smallest whole library you link for on-device verification.
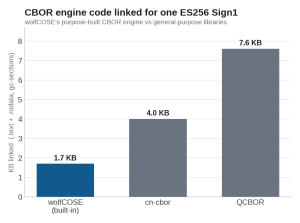
wolfCOSE keeps a tiny, purpose-built CBOR engine (1.7 KB) and does a bit more in the COSE layer; t_cose keeps a thinner COSE layer but leans on a CBOR engine that is more than 4x larger. Counted as a whole shippable library, which is what you actually link, wolfCOSE is the smallest at 6.8 KB. And this is not a strictness tradeoff or lack of implementation. Checking t_cose’s source it enforces the same RFC 9052 rules we do (critical-header handling, duplicate-label detection across protected and unprotected buckets). Meaning size tradeoffs in engines is simply a function of offloading to the different parts of the COSE and CBOR ecosystem.
Size: total footprint with a real embedded crypto backend
The COSE library is only part of the binary. The crypto backend dominates the total, so the honest comparison is across the real backends a COSE library can link, each built minimal from source for ES256: wolfCrypt, Mbed TLS, and OpenSSL.
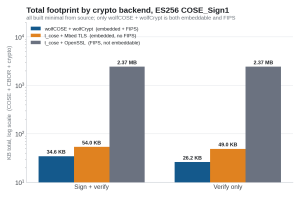
Figure 3. Total footprint by crypto backend on a log scale, ES256 COSE_Sign1, all built minimal from source. Only wolfCOSE + wolfCrypt is both embeddable and FIPS 140-3 validated.
| Stack | Sign + verify | Verify only | FIPS 140-3 | Embeddable |
|---|---|---|---|---|
| wolfCOSE + wolfCrypt | 34.6 KB | 26.2 KB | YES | YES |
| t_cose + Mbed TLS | 54.0 KB | 49.0 KB | NO | YES |
| t_cose + OpenSSL | 2.37 KB | 2.37 KB | Yes | No |
wolfCOSE plus wolfCrypt is about 36% smaller than t_cose + Mbed TLS for sign + verify and about 46% smaller for verify only. The verify-only number uses a new build profile, WOLFCOSE_LEAN_VERIFY, which compiles in only the COSE_Sign1 verify path. Similar to t_coses verify only macro as well. That is the common on-device case: a device verifies signed firmware or attestation while signing happens off-device on a server or HSM. It removes signing and the RNG entirely while keeping full RFC 9052 verification.
FIPS and embeddable: only one stack is both
This is where the backend choice gets real. t_cose forces a tradeoff. Paired with Mbed TLS you get an embeddable stack of about 54 KB, but Mbed TLS has no FIPS validation. Paired with OpenSSL you get FIPS, but OpenSSL links at about 2.37 MB (its provider architecture pulls in far more than the ES256 path) and does not run bare metal. wolfCOSE + wolfCrypt is the only stack here that is both: FIPS 140-3 certificate #4718 and about 35 KB on an MCU, with no second crypto library to integrate.
Size across languages
We also built the popular COSE libraries in other languages the same way: a minimal ES256 Sign1 verify, stripped.
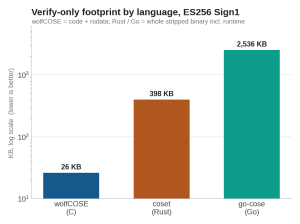
Figure 4. Verify-only footprint by language (log scale). C is the only one that fits a real MCU.
| Library | Language | Verify−only footprint |
|---|---|---|
| wolfCOSE | C | 26.2 KB (code + rodata) |
| coset + RustCrypto | Rust | 408 KB (whole binary) |
| go-cose | Go | 2.5 MB (whole binary) |
The Rust and Go numbers are whole stripped binaries because those runtimes are not separable the way C code is: Rust pulls in its std and core, and Go carries a roughly 1.5 MB runtime floor. The point is structural. For a real MCU, C is the only one of the three that fits comfortably, and OpenSSL-backed C does not fit either.
Speed
Throughput matters as much as size for attestation and secure-boot workloads. We benchmarked end-to-end COSE_Sign1 with each crypto backend in its fastest, assembly-optimized build (verified by inspecting the linked symbols). wolfCrypt uses its sp_256 AVX2 assembly, OpenSSL uses ecp_nistz256, Go’s standard library has amd64 ECDSA assembly, and RustCrypto’s p256 is portable Rust with no assembly. Mbed TLS has only generic bignum assembly and no P-256-specific assembly.
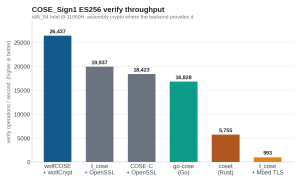
Figure 5. COSE_Sign1 ES256 verify throughput on x86_64, asm crypto where the backend provides it.
| Stack | Verify ops / s |
|---|---|
| wolfCOSE + wolfCrypt | 26,437 |
| t_cose + OpenSSL | 19,937 |
| COSE-C + OpenSSL | 18,423 |
| go-cose (Go) | 16,828 |
| coset + RustCrypto (Rust) | 5,755 |
| t_cose + Mbed TLS | 993 |
wolfCOSE + wolfCrypt is the fastest stack measured, ahead of even OpenSSL’s strong x86 assembly. The largest gap is against Mbed TLS, which is the most common embedded peer for t_cose.
wolfSSL vs Mbed TLS: the assembly story
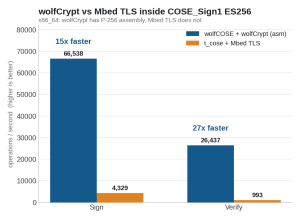
Figure 6. wolfCrypt vs Mbed TLS inside COSE_Sign1 ES256 on x86_64.
Head to head, wolfCOSE + wolfCrypt signs about 15x faster and verifies about 27x faster than t_cose + Mbed TLS (66,538 vs 4,329 sign/s; 26,437 vs 993 verify/s). This is the wolfSSL versus Mbed TLS assembly advantage carried into COSE. wolfCrypt has hand-written P-256 assembly. Mbed TLS does not. The same gap holds on an embedded ARM target, where wolfCrypt has Cortex-M assembly that Mbed TLS lacks. We measured that on real hardware next.
On a real MCU: STM32H563 (Cortex-M33 @ 250 MHz)
A desktop benchmark invites the obvious objection: show me a microcontroller. So we ran the same ES256 COSE_Sign1 verify on a NUCLEO-H563ZI (STM32H563ZI, Cortex-M33, 2 MB flash, 640 KB RAM) at 250 MHz, verifying the same fixed key and the same pre-signed message used above. Timing comes from the on-chip DWT cycle counter, so cycles/op is exact and clock-independent. Both stacks are verify-only with no RNG, both boot from the same 1.7 KB bare-metal scaffolding, and Mbed TLS runs in its fastest portable config (MBEDTLS_HAVE_ASM plus NIST optimization). wolfCrypt uses its Cortex-M Thumb P-256 assembly (WOLFSSL_SP_ARM_CORTEX_M_ASM).
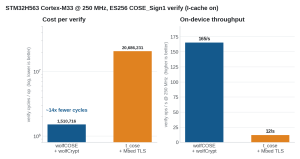
Figure 7. On-device ES256 COSE_Sign1 verify on STM32H563. Left: cycles per op (log). Right: ops/s at 250 MHz.
| Metric | wolfCOSE + wolfCrypt | t_cose + Mbed TLS |
|---|---|---|
| verify cycles / op | 1,510,716 | 20,686,231 |
| verify ops / s @ 250 MHz | ~165 | ~12 |
| flash (verify-only) | 44.2 KB | 45.6 KB |
| peak stack | 6.7 KB | 2.1 KB |
| peak heap | 0 (zero-alloc) | 5.2 KB |
| total RAM | ~6.7 KB | ~9.0 KB |
On the STM32H563, wolfCOSE + wolfCrypt verifies about 14x faster than t_cose + Mbed TLS (1.51M vs 20.7M cycles), because wolfCrypt has hand-written Cortex-M P-256 assembly and Mbed TLS runs its field arithmetic in portable C. (Measured with the instruction cache enabled, as on any real STM32H5 firmware; the on-device numbers cross-check the raw ECDSA-P256 verify on the same board.) Both stacks fit comfortably: about 2% of the 2 MB flash and 1% of the 640 KB RAM, leaving the rest of the chip for the application.
Two on-device points matter beyond raw speed. First, memory model: wolfCOSE and the wolfCrypt verify path allocate nothing, using only caller-provided buffers, so the entire RAM cost is about 6.7 KB of stack. Mbed TLS does about 5 KB of dynamic allocation per verify (its bignum layer grows its limbs with calloc, measured live at 5,160 bytes). It can serve that from a static buffer rather than the system heap, but there is no all-on-stack mode for ECDSA verify, so the allocation remains. Where malloc is prohibited, zero-allocation is a hard requirement, not a preference. Second, the same assembly advantage that wins on x86 carries to Cortex-M; it does not depend on a desktop CPU.
Putting the verify-only case together: most devices only ever verify, so this is the profile that ships most often. wolfCOSE + wolfCrypt wins on both axes. It is the smaller library (26.2 KB vs 49.0 KB total footprint for t_cose + Mbed TLS) and, on the STM32H563, about 14x faster, with zero heap. The size figure is the desktop verify-only build, the speed figure is the on-device measurement, and both point the same direction.
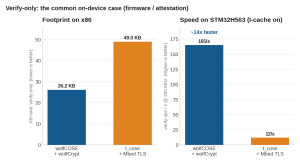
Figure 8. Verify-only is the common on-device case: a device verifies signed firmware or attestation while signing happens off-device. wolfCOSE + wolfCrypt is smaller (26.2 vs 49.0 KB) and about 14x faster on the STM32H563, with zero heap.
Everything to this point is classical ES256. The same library also does post-quantum signing, and the footprint cost is smaller than you would expect.
Post-quantum at the same cost: ML-DSA (FIPS 204)
wolfCOSE signs and verifies COSE_Sign1 with ML-DSA (FIPS 204, the standardized Dilithium) through wolfCrypt. None of the other C COSE libraries here offer post-quantum at all, and Mbed TLS has no PQ algorithms. The surprising part is the cost: measured the same way (dead-code eliminated, code + rodata), post-quantum COSE is essentially the same size as classical ES256.
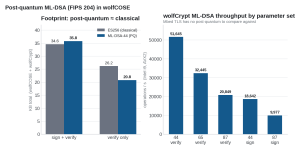
Figure 9. ML-DSA-44 footprint vs classical ES256 (left) and wolfCrypt ML-DSA throughput on Intel i9 with AVX2 (right).
| ML-DSA-44 build | wolfCOSE | wolfCrypt | Total | ES256 equivalent |
|---|---|---|---|---|
| sign + verify (WOLFCOSE_LEAN_MLDSA) | 6.6 KB | 29.2 KB | 35.8 KB | 34.6 KB |
| verify only (WOLFCOSE_LEAN_VERIFY_MLDSA) | 4.6 KB | 16.2 KB | 20.8 KB | 26.2 KB |
Post-quantum sign + verify lands within about 1 KB of classical ES256, and verify-only is actually smaller (20.8 vs 26.2 KB): wolfCOSE adds just 4.6 KB on top of wolfCrypt for ML-DSA verify, less than its ES256 glue, because ML-DSA skips the DER signature conversion ECDSA needs. Two build profiles ship for it: WOLFCOSE_LEAN_MLDSA (lean sign + verify) and WOLFCOSE_LEAN_VERIFY_MLDSA (smallest secure on-device PQ verify).
And it is fast. On the same Intel i9 with wolfCrypt’s AVX2 assembly, ML-DSA-44 verifies at 51,645/s, nearly 2x the 26,437/s of classical ES256 verify, because ML-DSA verification is cheaper than ECDSA’s. It signs at 18,642/s, and even ML-DSA-87 verifies at 20,849/s. wolfCrypt’s ML-DSA is vectorized (AVX2 on x86, ARM assembly on device); Mbed TLS has no post-quantum to compare against.
Why this is more than benchmarks
Size and speed are the measurable part. For the safety-critical and regulated markets COSE targets, wolfCOSE also brings what the others do not:
- A direct FIPS 140-3 path. wolfCOSE’s only crypto dependency is wolfCrypt, which holds FIPS 140-3 certificate #4718. There is a clean, direct path to a validated build with no second crypto library to wrangle.
- Drop-in PSA crypto via wolfPSA. wolfCrypt also implements the Arm PSA Crypto API, so on a device already built around Mbed TLS’s PSA crypto (for example under TF-M) you can swap in wolfPSA as the provider beneath wolfCOSE. You keep the PSA-based design and gain the FIPS 140-3 path, COSE, PQC, and wolfCrypt’s assembly speed in one stack, dropping straight into TF-M or PSA applications.
- A DO-178C path via wolfCOSE and wolfCrypt.
- MISRA-C. wolfCOSE is written to MISRA-C and checked in CI on every pull request, with documented deviations.
- Post-quantum, today. wolfCOSE supports CAVP certified ML-DSA (FIPS 204) signatures through wolfCrypt supporting full RFC 9964 compliance for ML-DSA.
- Zero heap allocation. Every operation uses caller-provided buffers, which matters where malloc is prohibited.
Bottom line
With one identical operation, dead-code elimination, and every library built the same way, the picture is consistent: wolfCOSE has the smallest COSE library code (6.8 KB), the smallest embedded total (34.6 KB sign + verify, 26.2 KB verify-only), and the fastest sign and verify. It is smaller because its CBOR engine is a fraction of QCBOR’s, and it is faster because wolfCrypt has the assembly the others lack. The speed advantage is not a desktop artifact: on an STM32H563 Cortex-M33 it verifies about 14x faster than t_cose + Mbed TLS with zero heap. It also delivers post-quantum ML-DSA at essentially the same footprint as classical ES256, plus a FIPS 140-3 path, a DO-178C path, and MISRA-C. That combination is unique among COSE implementations.
If you have questions about any of the above, please contact us at facts@wolfssl.com or call us at Download wolfSSL Now