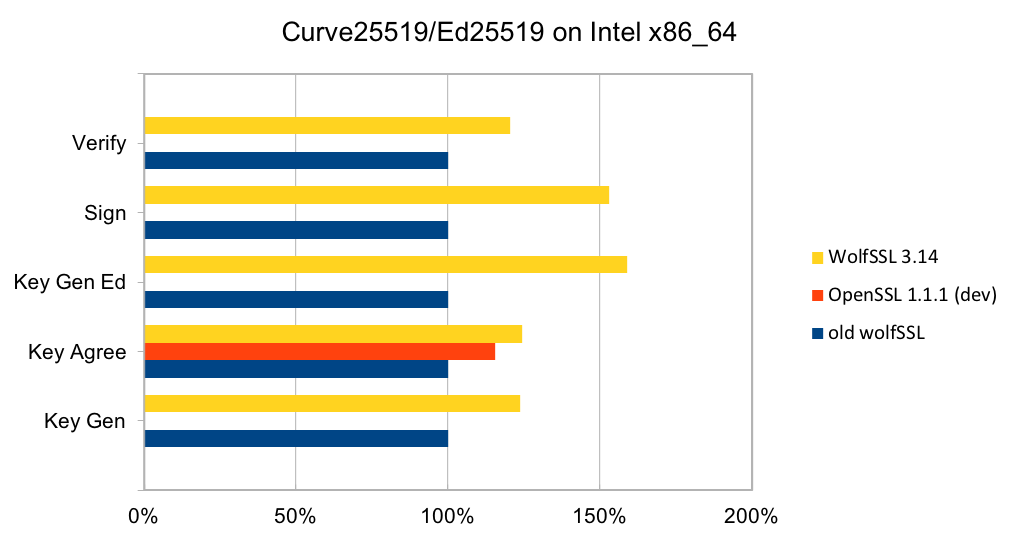
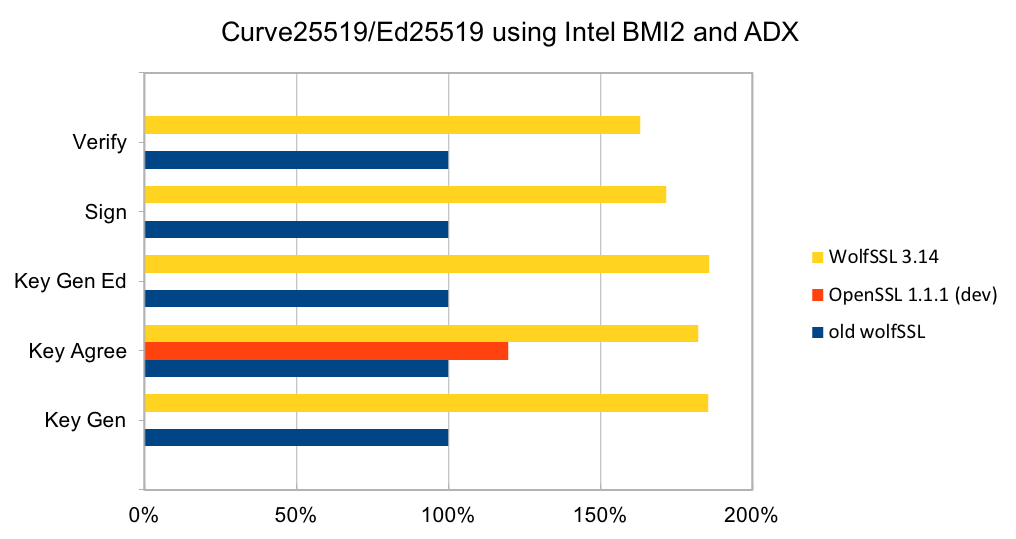
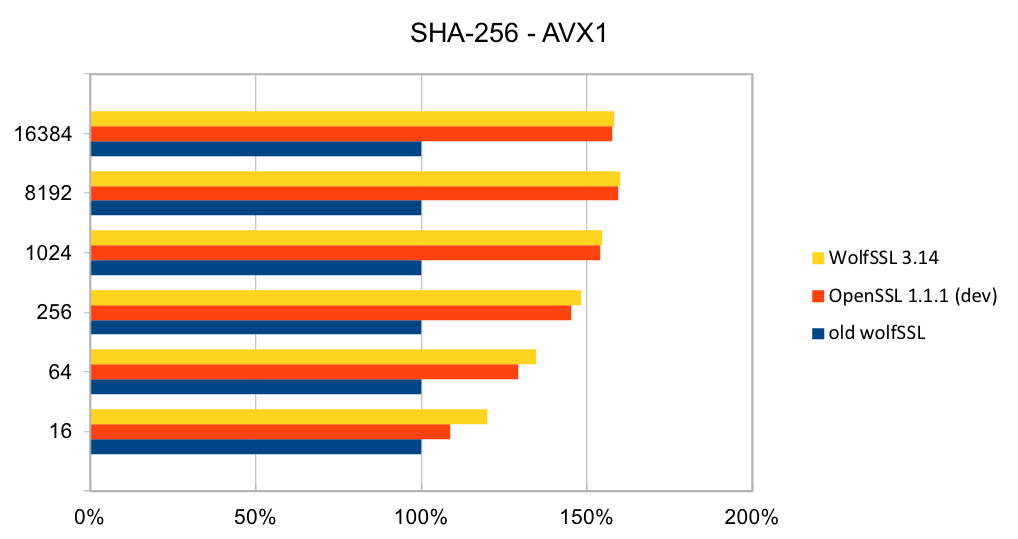
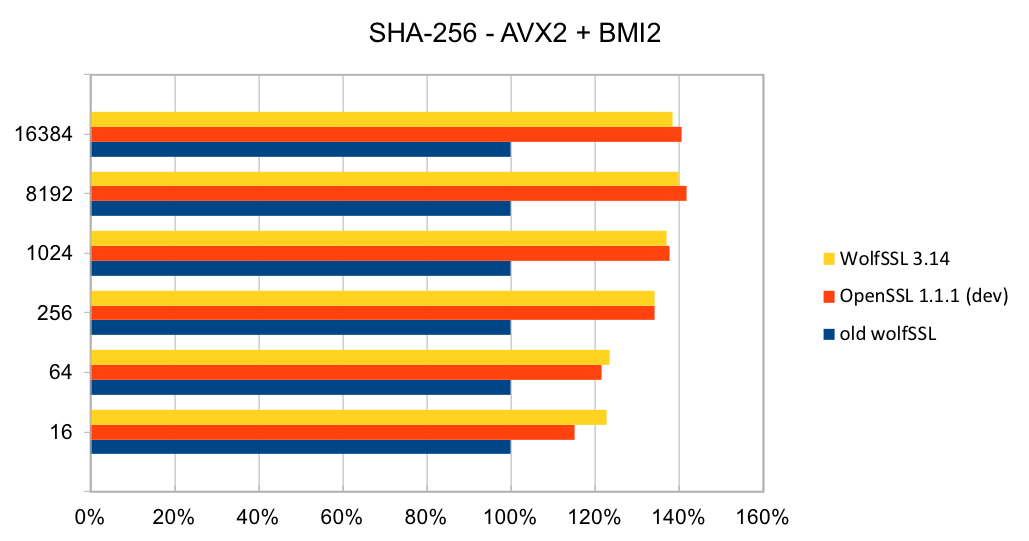
wolfSSL is committed to leveraging Continuous Integration in the design, delivery, and evaluation of our software – where development and testing are an ongoing process. As such, wolfSSL continues to make improvements to the quality of its testing throughout the software life-cycle to meet the needs of embedded IoT devices. Release 3.14.0 adds expanded unit testing for the following algorithms:
- Ed25519,
- Elliptic Curve Cryptography (ECC),
- AES CMAC,
- SHA 3, and
- RSA-PSS.
The addition of roughly fifty unit test functions increases our test coverage in the wolfSSL embedded TLS library. Unit testing along with the wolfCrypt testing functions provide both white and black box testing methodology in an effort to increase the security of the software. wolfSSL strives to be the most thoroughly tested SSL/TLS library available. Our testing process is intended to rigorously examine the execution paths of our software as well as test the correctness of the algorithms implemented.
For a more comprehensive view into our testing process, feel free to read our previous blog post on the different types of testing we do at wolfSSL! And, as always, please contact us at facts@wolfssl.com with any questions.