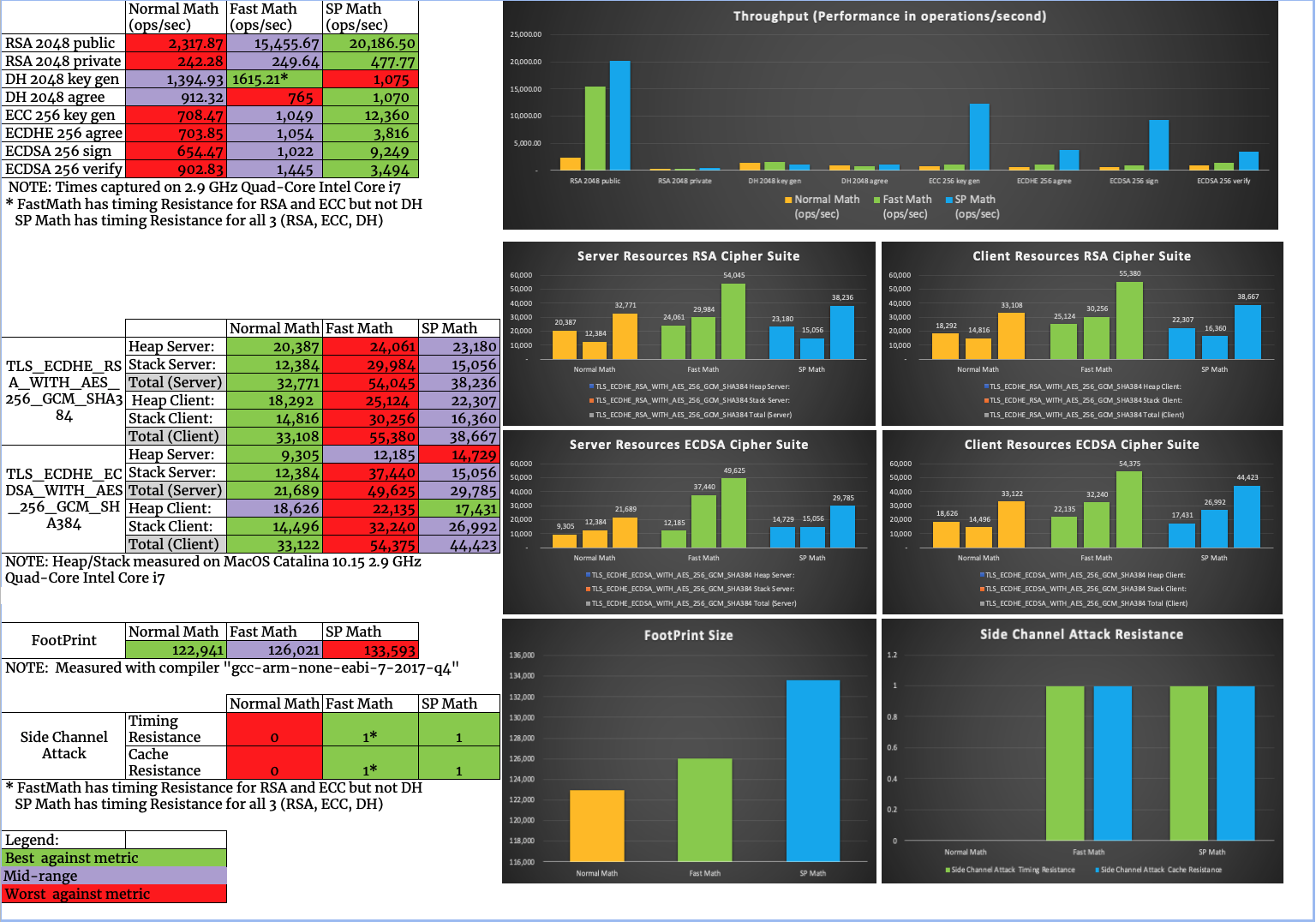
wolfSSL has a new implementation of the multi-precision math library that is an improvement in every way. The code is in sp_int.c and can be turned on with WOLFSSL_SP_MATH_ALL or -–enable-sp-math-all. Previously the choice was between the implementations in integer.c and tfm.c.
The small or Integer implementation (--disable-fastmath) was written to be simple, to have small code size, and use small amounts of memory. And it does a great job! By using simple, small algorithms and dynamically resizing the memory holding the number the code is perfect for embedded applications. Certain industries have specific coding standards that require no dynamic memory allocation and therefore this implementation is not suitable without the static memory allocator. Also the implementation is not hardened against side-channel attacks. This will not matter for embedded applications that have no cryptographic operations that are externally measurable.
The fast or TFM implementation --enable-fastmath (USE_FAST_MATH), --enable-fasthugemath (USE_FAST_MATH, TFM_SMALL_SET, TFM_HUGE_SET), is based on TomsFastMath – a public domain, large integer arithmetic library. The code was written to be fast. This means the code is more complicated and larger with case specific implementations. Also, the size of data for a number is fixed. Therefore, no dynamic reallocations. The code is hardened against side-channels (TFM_TIMING_RESISTANT) which makes it suitable for wider use. This implementation is perfect for embedded applications with more memory or mobile apps! Basing the implementation on an external code base does have its disadvantages though. Every time we update our code, we drift away from the original and bringing back the external changes takes longer and longer.
So why a new implementation? An implementation that has the best of both worlds – able to be small or fast – and is written from scratch, by us, and maintained, by us, means that we have everything we need in one place. Oh, and did we mention it can be compiled to be smaller and faster than integer.c, or to be smaller and faster than tfm.c?
The new SP Math All (sp_int.c) implementation can be compiled to be small, fast. or very fast and huge. Like the fast implementation, the size of data for a number is fixed and therefore there are no dynamic reallocations. When compiled for small code size, only the simple algorithms for basic operations are included but far less speed is sacrificed! There is also fast implementations that are included with the huge option which include code specifically for larger numbers like 1024-bits and above. To get the code running as fast as possible, snippets of assembly code are used. A wide range of platforms are supported including: x64, x86, Aarch64, ARM32, Cortex-M4, PPC64, PPC, MIPS64, MIPS, RISCV64, RISCV32 and S390X. SP Math All code will use implementations hardened against side-channels by default.
A brief summary of the implementations is below:
| Integer | TFM | SP Math All |
| Number Data | Dynamic | Fixed | Fixed |
| Memory Usage | Small | Large/Huge | Small/Large/Huge |
| Speed | Slow | Fast/Very Fast | Slow/Fast/Very Fast |
| Assembly Code | None | Few Platforms | Many Platforms |
| Hardened Impls | No | Yes | Yes |
In the next blog, we will take a look at the comparison of performance characteristics of SP Math All and Integer implementations. If you have any commentary or feedback, or have questions about using the wolfSSL embedded SSL/TLS library in your project.
If you have any questions or run into any issues, contact us at facts@wolfssl.com, or call us at +1 425 245 8247.